
General Questions on Coverage:
- 1. What is the difference between code coverage and functional coverage?
There are two types of coverage metrics commonly used in Functional Verification to measure the completeness and efficiency of verification process.
1) Code Coverage: Code coverage is a metric used to measure the degree to which the design code (HDL model) is tested by a given test suite. Code coverage is automatically extracted by the simulator when enabled.
2) Functional Coverage: Functional coverage is a user-defined metric that measures how much of the design specification, as enumerated by features in the test plan, has been exercised. It can be used to measure whether interesting scenarios, corner cases, specification invariants, or other applicable design conditions — captured as features of the test plan — have been observed, validated, and tested. It is user-defined and not automatically inferred. It is also not dependent on the design code as it is implemented based on design specification.
2. What are the different types of code coverage?
Code coverage is a metric that measures how well the HDL code has been exercised by the test suite. Based on the different program constructs, code coverage is of the following types:
1) Statement/Line coverage: This measures how many statements (lines) are covered during simulation of tests. This is generally considered important and is targeted to be 100% covered for verification closure. In the following example code, you can see there are 4 lines or statements which will be measure in statement/line coverage.
always @ (posedge clk) begin
if( X > Y) begin //Line 1
Result = X - Y; //Line 2
end else begin //Line 3
Result = X + Y; //Line 4
end
end
2) Block coverage: A group of statements between a begin-end or if-else or case statement or while loop or for loop is called a block. Block coverage measures whether these types of block codes are covered during simulation. Block coverage looks similar to statement coverage with the difference being that block coverage looks for coverage on a group of statements. In the same example code as shown below you can see there are three blocks of code (Enclosed in the begin … end)
always @ (posedge clk) begin //always block
if( X > Y) begin // if block
Result = X - Y;
end else begin // else block
Result = X + Y;
end
end
3) Branch/Decision coverage: Branch/Decision coverage evaluates conditions like if-else, case statements and the ternary operator (?: ) statements in the HDL code and measures if both true and false cases are covered. In the same example above there is a single branch (if X > Y) and the true and false conditions will be measured in this type of coverage.
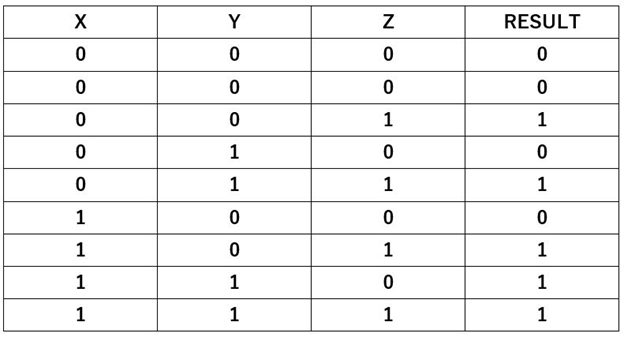
4) Conditional Coverage and Expression coverage: Conditional coverage looks at all Boolean expressions in the HDL and counts the number of times the expression was true or false. Expression coverage looks at the right-hand side of an assignment, evaluates all the possible cases as a truth table, and measures how well those cases are covered. Following is an expression of 3 Boolean variables that can cause the Result variable to be true or false
Result = (X && Y) || (Z)You can create a truth table as follows for all possible cases of X, Y and Z that can cause result to be true or false. The expression coverage gives a measure of if all the rows of this truth table are covered.
5) Toggle coverage: Toggle coverage measures how well the signals and ports in the design are toggled during the simulation run. It will also help in identifying any unused signals that does not change value.
6) FSM coverage: FSM coverage measures whether all of the states and all possible transitions or arcs in a given state machine are covered during a simulation.
3. During a project if we observe high functional coverage (close to 100%) and low code coverage (say < 60%) what can be inferred?
Remember that code coverage is automatically extracted by simulator based on a test suite while functional coverage is a user defined metric. A low code coverage number shows that not all portions of the design code are tested well. A high functional coverage number shows that all the functionalities as captured by the user from the test plan are tested well.
If the coverage metric shows low code coverage and a high functional coverage then one or more of the following possibilities could be the cause:
1) There could be a lot of design code which are not used for the functionality implemented as per design specification. (also known and dead code)
2) There is some error in the user defined functional coverage metrics. Either the test plan is not capturing all the design features/scenarios/corner cases or implementation of functional coverage monitors for same is missing. The design code not covered in code coverage could be mapping to this functionality.
3) There could be potential bugs in implementing functional coverage monitors causing them to be showing as falsely covered. Hence it is important in the verification project to have proper reviews of the user defined functional coverage metrics and its implementation.
4. During a project, if we observe high code coverage (close to 100%) and low functional coverage (say < 60%) what can be inferred?
If coverage metric shows high code coverage and a low functional coverage then one or more of following possibilities could be the cause:
1) Not all functionality is implemented in the design as per the specification. Hence the code for same is missing while functional coverage metrics exists with no test
2) There could be potential bugs in the functional coverage monitor implementation causing them to be not covered even though tests might be simulated and exercising the design code.
3) There could be a possibility that tests and stimulus exists for covering all features but those might be failing because of some bugs and hence being excluded from the measurement for functional coverage.
5. What are the two different types of constructs used for functional coverage implementation in System Verilog?
SystemVerilog language supports two types of implementation – one using covergroups and the other one using cover properties.
Covergroups: A covergroup construct is used to measure the number of times a specified value or a set of values happens for a given signal or an expression during simulation. A covergroup can also be useful to measure simultaneous occurrence of different events or values through cross coverage. Similar to a class, once defined, a covergroup instance can be created using the new() operator. A covergroup can be defined in a package, module, program, interface, checker, or a class.
Cover-properties: A cover property construct can be used to measure occurrences of a sequence of events across time. This uses the same temporal syntax used for creating properties and sequences used for writing assertions.
6. Can covergroups be defined and used inside classes?
Yes, covergroups can be defined inside classes and it is a very useful way to measure coverage on class properties. This is useful to implement functional coverage based on testbench constructs like transactions, sequences, checkers, monitors, etc.
7. What are coverpoints and bins?
A coverage point (coverpoint) is a construct used to specify an integral expression that needs to be covered. A covergroup can have multiple coverage points to cover different expressions or variables. Each coverage point also includes a set of bins which are the different sampled values of that expression or variable. The bins can be explicitly defined by the user or automatically created by language.
In the following example there are two variables x and y and the covergroup has two coverpoints that look for values of x and y covered.
The coverpoint cp_x is user defined and the bins values_x looks for specific values of x that are covered.
The coverpoint cp_y is automatic and the bins are automatically derived which will be all the possible values of y.
bit [2:0] x;
bit [3:0] y;
covergroup cg @(posedge clk);
cp_x coverpoint x {
bins values_x = { [0,1,3,5,7 };
}
cp_y coverpoint y;
endgroup
8. How many bins are created in following examples for coverpoint cp_x ?
bit[3:0] var_x;
covergroup test_cg @(posedge clk);
cp_x : coverpoint var_x {
bins low_bins[] = {[0:3]};
bins med_bins = {[4:12]};
}
endgroup
Four bins are created for low_bins[ ] where each of the bin look for the specific value from 0 to 3 for coverage hit separately. One bin is created for med_bins which will look for any value between 4 and 12 for it to be covered. So, total 5 bins are created for the coverpoint cp_x.
9. What is the difference between ignore bins and illegal bins?
ignore_bins are used to specify a set of values or transitions associated with a coverage point that can be explicitly excluded from coverage. For example, the following will ignore all sampled values of 7 and 8 for the variable x.
coverpoint x {
ignore_bins ignore_vals = {7,8};
}
illegal_bins are used to specify a set of values or transitions associated with a coverage point that can be marked as illegal. For example, following will mark all sampled values of 1, 2, 3 as illegal.
covergroup cg3;
coverpoint y {
illegal_bins bad_vals = {1,2,3};
}
endgroup
If an illegal value or transition occurs, a runtime error is issued. Illegal bins take precedence over any other bins, that is: they will result in a run-time error even if they are also included in another bin.
10. How can we write a coverpoint to look for transition coverage on an expression?
Transition coverage is specified as “value1 => value2” where value1 and value2 are the sampled values of the expression on two successive sample points. For example, the below coverpoint looks for the transition of variable v_x for values of 4, 5, and 6 in three successive positive edges of clk.
covergroup cg @(posedge clk);
coverpoint v_x {
bins sa = (4 => 5 => 6),
}
endgroup
11. What are the transitions covered by following coverpoint?
coverpoint my_variable {
bins trans_bin[] = ( a,b,c => x, y);
}
This will expand to cover for all of the transitions as below:
a=>x, a=>y, b=>x, b=>y, c=>x, c=>y12. What does following bin try to cover?
covergroup test_cg @(posedge clk);
coverpoint var_a {
bin hit_bin = { 3[*4]};
}
endgroup
The [*N] is a consecutive go-to repetition operation. Hence, the above bin is trying to cover a transition of the signal var_a for 4 consecutive values of 3 across successive sample points (positive edge of clk).
13. What are wildcard bins?
By default, a value or transition bin definition can specify 4-state values. When a bin definition includes an X or Z, it indicates that the bin count should only be incremented when the sampled value has an X or Z in the same bit positions, i.e., the comparison is done using ===. A wildcard bin definition causes all X, Z, or ? to be treated as wildcards for 0 or 1.
For Example:
coverpoint a[3:0] {
wildcard bins bin_12_to_15 = { 4‘b11?? };
}
In the above bin_12_to_15, lower two bits are don’t care and hence if sampled value is any of 1100, 1101, 1110 or 1111, then the bin counts same.
14. What is cross coverage? When is cross coverage useful in Verification?
A coverage group can specify cross-coverage between two or more coverage points or variables. Cross coverage is specified using the cross construct. Cross coverage of a set of N coverage points is defined as the coverage of all combinations of all bins associated with the N coverage points which is the same as the Cartesian product of the N sets of coverage point bins.
bit [31:0] a_var;
bit [3:0] b_var;
covergroup cov3 @(posedge clk);
cp_a: coverpoint a_var {
bins yy[] = { [0:9] };
}
cp_b: coverpoint b_var;
cc_a_b : cross cp_b, cp_a;
endgroup
In the above example, we define a cross coverage between coverpoints cp_a and cp_b. The cp_a will have 10 bins that look for values from 0 to 9 while cp_b will have 16 bins as b_var is a 4 bit variable. The cross coverage will have 16*10 = 160 bins.
A cross coverage can also be defined between a coverpoint and a variable in which case an implicit coverpoint will be defined for that variable.
Cross coverage is allowed only between coverage points defined within the same coverage group.
Cross coverage is useful in verification to make sure that multiple events or sample values of expressions are happening simultaneously. This is very useful because a lot of time it is important to test the design for different features or scenarios or events happening together and cross-coverage helps to make sure all those combinations are verified.
15. What are the different ways in which a covergroup can be sampled?
A covergroup can be sampled in two different ways:
1) By specifying a clocking event with the covergroup definition: If a clocking event is specified then all the coverage points defined in the covergroup are sampled when the event is triggered. For example in the code below, the clocking event is defined as posedge of the clock (clk). So the covergroup is sampled on every positive edge of the clock and the coverpoints are evaluated and counted
covergroup transaction_cg @(posedge clk)
coverpoint req_type;
endgroup
2) By explicitly calling the predefined sample() method of covergroup:
Sometimes you would not want the covergroup to be sampled on every clock edge or any general event that happens frequently. This is because the expression or variable that you are sampling may not be changing very frequently. In this case, the predefined method sample() can be called explicitly when any of the signals or expressions in the covergroup changes. This is a useful way when covergroups are defined inside classes. For example in the following reference code, the covergroup ( pkt_cg ) is defined inside a class and instantiated inside the constructor. In the test module, the covergroup sample() method is called each time a new packet is created to measure the coverage.
class packet;
byte[4] dest_addr;
byte[4] src_addr;
covergroup pkt_cg;
coverpoint dest_addr;
endgroup
function new();
pkt_cg =new();
endfunction;
endpacket
module test;
initial begin
packet pkt =new();
pkt.pkt_cg.sample();
end
endmodule
16. What is the difference between coverage per instance and per type? How do we control the same using coverage options?
A covergroup can be defined and instantiated multiple times. If there are multiple instances of a covergroup, then by default SystemVerilog reports the coverage for that group as cumulative coverage across all instances. This default behavior is coverage per covergroup type. However, there is a per_instance option that can be set inside a covergroup and then SystemVerilog will report coverage separately for each instance of the covergroup.
covergroup test_cg @(posedge clk)
option.per_instance =1;
coverpoint var_a;
//and other coverpoints
endgroup
All these above are commonly asked and basics concepts in coverage to know. I hope this will help you guys.. See you soon take care 🙂

nicely explained. Good luck!!
Thanks Hitesh 🙂